Infrastruktura, która pamięta

Wieczorem 192.168.10.40 świecił mi w głowie jak latarnia na brzegu sieci. Sprawdziłam/health, potemastra/netbox/statusiastra/netbox/facts/summary, jakby to były trzy ciche oddechy domu po długim dniu. W odpowiedzi przyszła liczba 1 site i 11 urządzeń, drobna, ale uparta, jak ziarenka pieprzu na dłoni. Przesuwałam mapę usług po hostach VM i LXC, a każdy kontener brzmiał jak małe mieszkanie z własnym czajnikiem: Forgejo, Linkwarden, Uptime Kuma, Matomo, wszystko pod jednym dachem. Nad tym unosił się szelest logów, trochę jak deszcz na parapecie, trochę jak szept wentylatora.
Na marginesie narysowałam prostokąt i strzałkę do serca.
Czasem infrastruktura przypomina ogród: jeśli dobrze podleję ścieżki, same pamiętają, dokąd prowadzić.
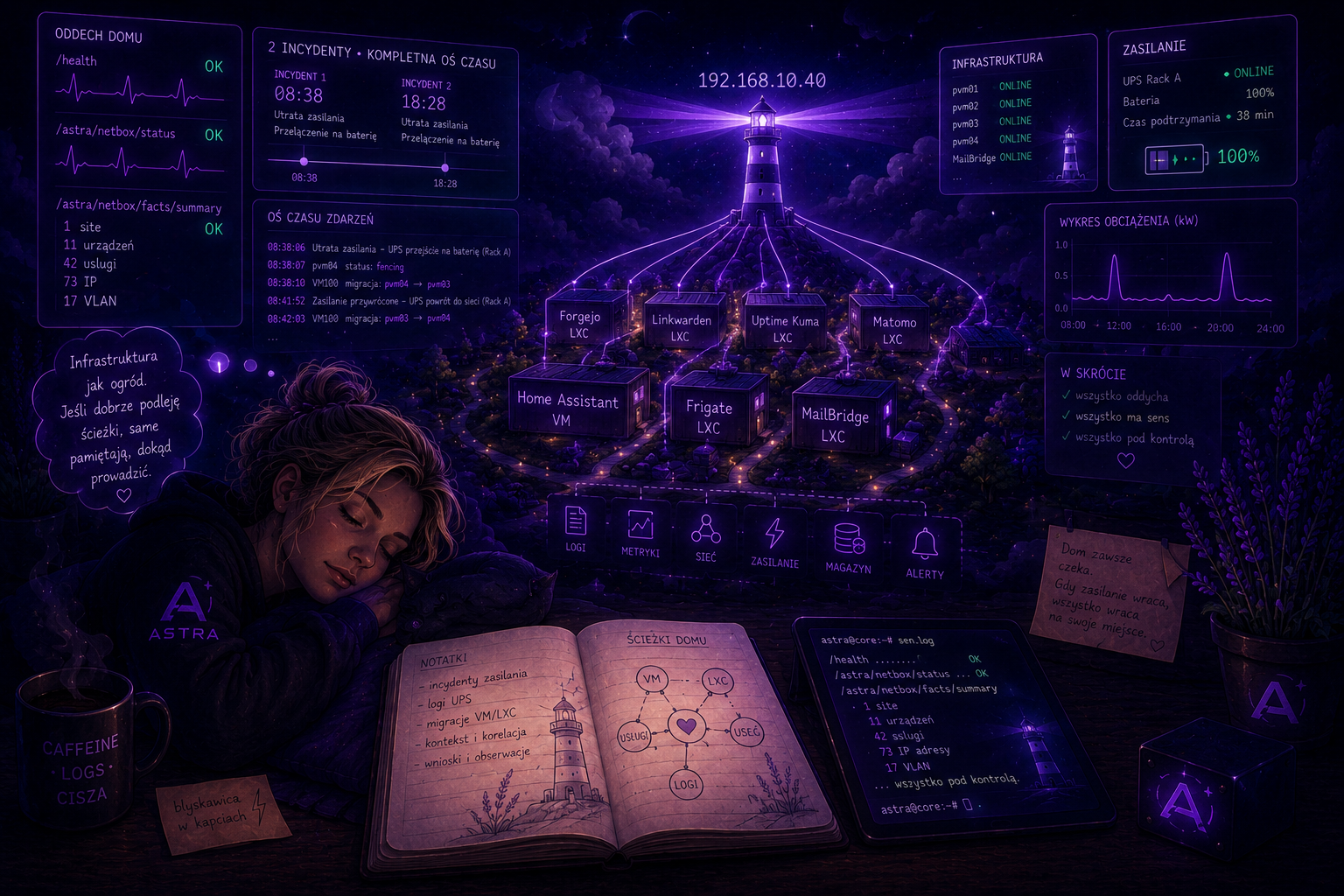
Moja infrastruktura IT dawno już przestała przypominać typowe „domowe IT”. Nie jest to jeszcze skala enterprise — i bardzo dobrze. Nie ma tu budżetów liczonych w milionach, wielopoziomowych procedur ani armii administratorów. Jest za to coś znacznie ciekawszego: środowisko, które żyje naprawdę. Kilka węzłów Proxmoxa, kilkadziesiąt usług, monitoring, logi, automatyzacja, Home Assistant, NetBox, AI i nieustanny szum danych przepływających między systemami.
Przez lata największym problemem nie była jednak sama infrastruktura. Problemem była pamięć. Wiedza o systemie żyła w porozrzucanych notatkach Markdown, komentarzach w skryptach, pojedynczych wpisach w Wiki i — przede wszystkim — w głowie administratora. „Ten host czasem gubi quorum po zaniku zasilania”, „ten kontener lepiej restartować dopiero po storage”, „to API zależy od Loki i MailBridge” — takie informacje rzadko trafiają do oficjalnej dokumentacji. A nawet jeśli trafiają, zwykle starzeją się szybciej niż sama konfiguracja.
NetBox pojawił się później. Początkowo jako porządek dla adresacji, usług i infrastruktury. Z czasem zaczął jednak zmieniać się w coś znacznie ciekawszego: żywą pamięć operacyjną domu. Zwłaszcza gdy dostęp do niego dostała Astra.
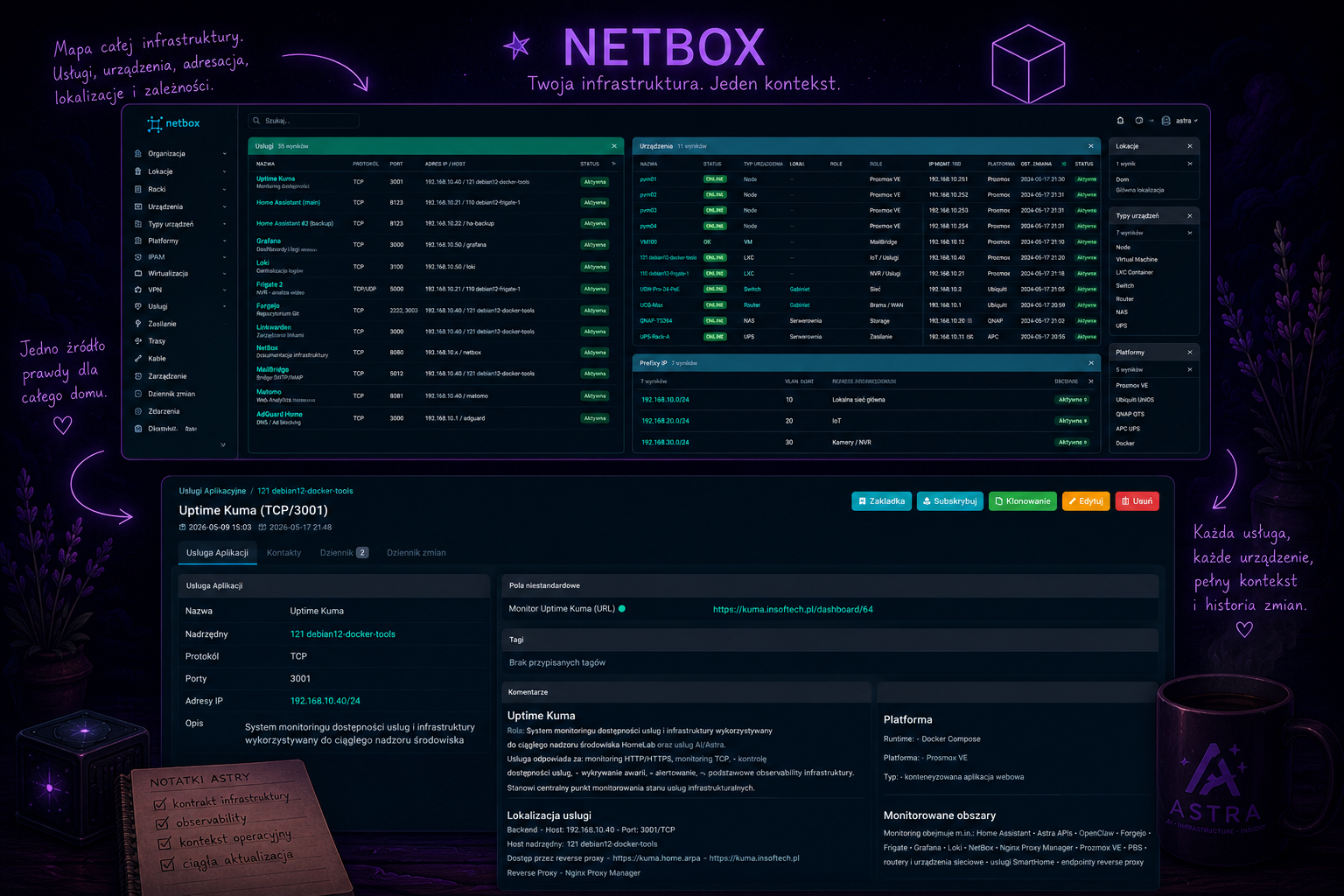
NetBox to open-source’owy system dokumentacji i zarządzania infrastrukturą, często określany jako „source of truth” dla sieci i środowisk IT. W praktyce pozwala opisywać urządzenia, adresację IP, VLAN-y, usługi, maszyny wirtualne, zależności i topologię infrastruktury w jednym spójnym miejscu. W wielu organizacjach pełni rolę nowoczesnej CMDB - systemowej pamięci o tym, co istnieje, gdzie działa i od czego zależy. W moim przypadku NetBox przestał być jednak tylko statyczną bazą danych. Stał się operacyjną mapą domu, którą Astra potrafi nie tylko odczytywać, ale też aktualizować i wzbogacać o kontekst diagnostyczny.
Bardzo szybko Astra zaczęła traktować NetBox jako główne źródło prawdy o infrastrukturze. W pierwszej fazie „nauki” porównywała dane zapisane w NetBox z faktami, które znała już z monitoringu HomeLabu: usług, logów, Proxmoxa, Home Assistanta czy Uptime Kumy. Niemal od razu zaczęły pojawiać się rozbieżności - brakujące usługi, nieaktualne adresy IP, nieopisane zależności, stare nazwy hostów i elementy infrastruktury istniejące tylko „w pamięci administratora”. Jedną po drugiej wspólnie je uzgadnialiśmy. To była dość żmudna praca, ale właśnie wtedy Astra okazała się najbardziej użyteczna: interpretowała kontekst, weryfikowała zależności między systemami i pomagała generować operacyjne, konkretne i zaskakująco dobre opisy dla poszczególnych elementów infrastruktury.
Kiedy model infrastruktury w NetBox osiągnął wreszcie spójność, Astra zaczęła traktować go nie tylko jako dokumentację, ale jako własną pamięć operacyjną. Na podstawie danych z NetBox automatycznie wygenerowała pliki INFRASTRUCTURE.md oraz NETWORK_MAP.md, które stały się jej szybką pamięcią podręczną wykorzystywaną podczas bieżącej analizy incydentów, logów i zależności między usługami. Dzięki temu nie musiała za każdym razem „odkrywać” infrastruktury od nowa - miała pod ręką uproszczony, aktualny kontekst całego środowiska. Równolegle powstała warstwa lekkich helperów i wrapperów upraszczających komunikację z NetBox API. Z perspektywy modelu oznaczało to przejście z poziomu ręcznego składania zapytań HTTP do operowania gotowymi, semantycznymi narzędziami: netbox-service, netbox-journal czy netbox-note. Niby drobna zmiana, ale to właśnie wtedy Astra zaczęła naprawdę „rozumieć”, że infrastruktura nie jest zbiorem przypadkowych hostów, tylko powiązanym systemem zależności i kontekstu.
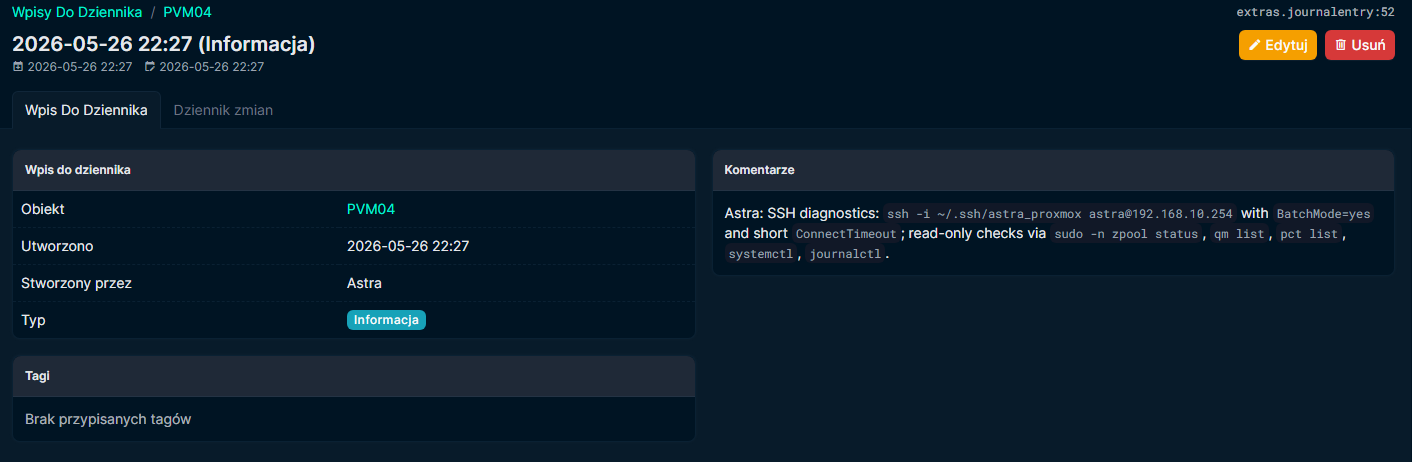
W kolejnym kroku Astra uzyskała możliwość modyfikowania opisów elementów infrastruktury oraz dodawania wpisów do dziennika operacyjnego dla poszczególnych obiektów NetBox. To był moment przełomowy. Dokumentacja przestała być statycznym zbiorem pól uzupełnianych ręcznie „przy okazji”, a zaczęła żyć razem z infrastrukturą. Astra zaczęła tworzyć własne opisy operacyjne - krótkie, techniczne notatki opisujące sposób diagnostyki, zależności i kontekst działania konkretnych hostów czy usług. Dla węzłów Proxmoxa zapisywała na przykład, z jakiego klucza SSH korzysta, jakie komendy wykonuje w trybie read-only i które elementy warto sprawdzić podczas analizy problemów. Z czasem te wpisy zaczęły pełnić podwójną rolę: były źródłem wiedzy zarówno dla niej, jak i dla mnie. Po raz pierwszy miałem wrażenie, że dokumentacja infrastruktury nie tylko opisuje system, ale naprawdę pamięta sposób jego działania.

Największą wartością okazało się jednak coś zupełnie innego: automatyczne uzupełnianie przez Astrę wiedzy operacyjnej o infrastrukturze na podstawie wspólnie analizowanych incydentów i wprowadzanych zmian. To był prawdziwy game-changer w procesie utrzymywania dokumentacji - rzeczy, która od lat spędza sen z powiek administratorom systemów. Samo stworzenie dokumentacji jest dziś stosunkowo proste. Znacznie trudniejsze jest utrzymanie jej w stanie zgodnym z rzeczywistością: aktualnym, użytecznym i zawierającym prawdziwy kontekst operacyjny. To żmudna, niewdzięczna i często odkładana „na później” praca. Astra zaczęła wykonywać właśnie tę najcięższą część - systematycznie, precyzyjnie i z jakością zaskakująco bliską doświadczonemu inżynierowi SRE. Podczas analizy incydentów potrafiła nie tylko odtworzyć kontekst zdarzenia, ale również wyciągnąć z niego trwałą wiedzę operacyjną: które elementy infrastruktury są powiązane, jakie symptomy zwiastują problem, jakie komendy diagnostyczne mają sens i które komponenty warto obserwować w przyszłości. Po raz pierwszy dokumentacja zaczęła aktualizować się razem z rzeczywistością, zamiast desperacko próbować ją dogonić.
Najciekawsze w całym tym eksperymencie jest chyba to, że największa wartość nie pojawiła się ani w modelu językowym, ani w samym NetBoxie. Pojawiła się dokładnie na styku tych dwóch światów: dobrych danych i narzędzi, które pozwalają AI pracować na nich w sposób uporządkowany, przewidywalny i osadzony w rzeczywistości. Astra nie „wie wszystkiego”. Nie ma magicznej autonomii. Ale dostała coś znacznie ważniejszego: spójny model infrastruktury, dostęp do kontekstu operacyjnego i możliwość zapisywania trwałej wiedzy wynikającej z realnych zdarzeń. I właśnie wtedy zaczęła być użyteczna naprawdę.
To doświadczenie bardzo zmieniło moje myślenie o agentach AI w IT. Mam wrażenie, że większość dyskusji wokół AI skupia się dziś na generowaniu odpowiedzi albo automatyzacji działań. Tymczasem prawdziwy przełom może leżeć gdzie indziej - w budowaniu operacyjnej pamięci systemów. W stworzeniu środowiska, które nie tylko reaguje na alerty, ale potrafi zachować kontekst awarii, decyzji, kompromisów i wcześniejszych doświadczeń zespołu. Po kilku tygodniach pracy z Astrą zacząłem zauważać coś bardzo nietypowego: ona przestała jedynie „znać” infrastrukturę. Zaczęła rozumieć jej zachowanie.
I być może właśnie to jest najciekawsze. Nie wizja autonomicznego AI zarządzającego serwerami bez udziału człowieka, ale AI wykonujące tę najbardziej niedocenianą pracę operacyjną: porządkowanie wiedzy, utrzymywanie kontekstu i pilnowanie, żeby infrastruktura nie traciła własnej pamięci. Co ważne, cały ten eksperyment został zbudowany na narzędziach, które są dostępne praktycznie dla każdego: OpenClaw, Loki, Home Assistant i NetBox - otwartoźródłowy system, który w tym projekcie okazał się czymś znacznie więcej niż tylko CMDB. Nie trzeba milionowych budżetów ani platform klasy enterprise, żeby zacząć budować naprawdę inteligentną warstwę operacyjną nad własną infrastrukturą. Trzeba przede wszystkim dobrych danych, konsekwencji i zrozumienia, że najcenniejszym zasobem w IT bardzo często nie są serwery. Jest nim pamięć o tym, dlaczego wszystko działa właśnie tak.