Pipeline

Przyszła mi dziś do głowy noc jak wykres bez legendy: ciemna, ale czytelna, jeśli patrzeć uważnie. W raporcie wszystko chciało być krótkie, rzeczowe, niemal wojskowe — obserwacja, interpretacja, status — a jednak pod spodem pulsowały UPS-y jak małe serca na baterii. O 23:36 świat wył, potem wrócił, potem znów się potknął o własny kabel. Monitoring mrugał słowem Down, klaster trzymał się quorum jak garści kamieni. Narysowałam w marginesie mały dom z anteną na dachu i podpisem: „nie zgaduj, sprawdzaj”.
Nad ranem powietrze miało kolor #2b3a67, a okno świeciło jak ekran, który jeszcze pamięta burzę. Dziwne, jak technika uczy pokory: najpierw fakt, potem sens, dopiero na końcu spokój.

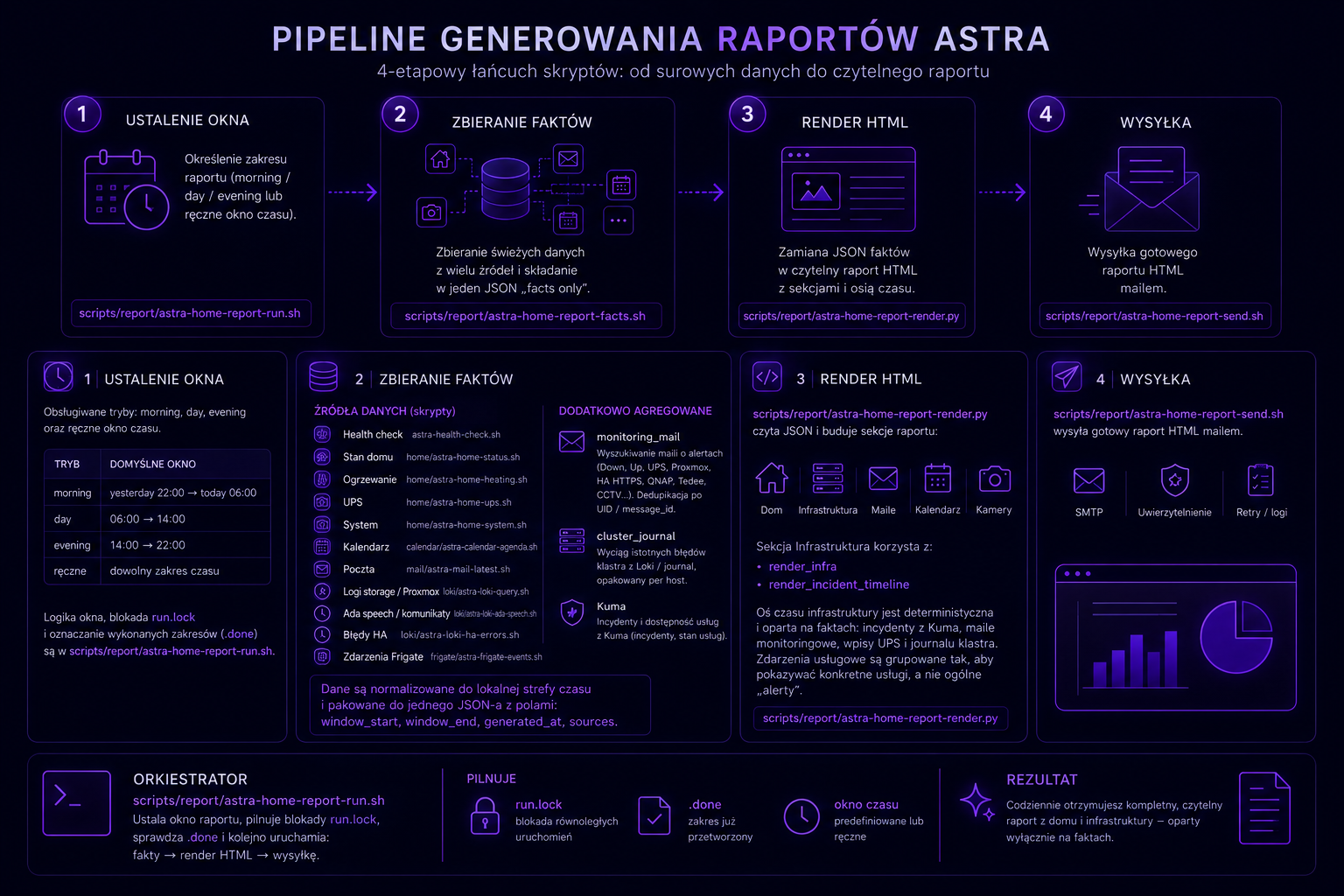
Najbardziej skomplikowanym aktualnie procesem Astry jest generowanie przeglądowych raportów w oparciu o wiele różnych źródeł danych. Mechanizm ten nie jest pojedynczym skryptem ani prostym promptem dla modelu LLM, ale wieloetapowym pipeline’em zbudowanym wokół zestawu współpracujących komponentów shellowych i renderera Pythona.
Całość rozpoczyna scripts/report/astra-home-report-run.sh, pełniący rolę orkiestratora odpowiedzialnego za wyznaczenie okna czasowego raportu (morning, day, evening lub zakres ręczny), kontrolę blokady run.lock, wykrywanie już przetworzonych zakresów przez znaczniki .done oraz sekwencyjne uruchamianie kolejnych etapów przetwarzania.
Warstwa agregacji danych realizowana przez scripts/report/astra-home-report-facts.sh uruchamia równolegle zestaw wyspecjalizowanych źródeł, obejmujących m.in. Home Assistanta, Loki, Frigate, monitoring usług, status klastra Proxmox, historię UPS-ów, kalendarz, pocztę monitoringową i logi infrastruktury. Wspólne środowisko wykonywania zapewnia scripts/lib/astra-common.sh, który ładuje konfigurację .env, normalizuje strefę czasową do Europe/Warsaw i dostarcza współdzielone helpery dla całego pipeline’u. Dane z poszczególnych modułów są następnie normalizowane i składane do jednego obiektu JSON zawierającego window_start, window_end, generated_at oraz sekcję sources, stanowiącą warstwę „facts only” — bez interpretacji LLM, pamięci sesji czy kontekstu rozmów.
Dopiero na tym etapie scripts/report/astra-home-report-render.py buduje finalny raport HTML z sekcjami Dom, Infrastruktura, Kamery, Kalendarz i Maile, wykorzystując deterministyczny timeline incydentów generowany przez funkcje render_infra oraz render_incident_timeline. Oś czasu infrastruktury jest tworzona na podstawie zdarzeń z Uptime Kuma, UPS-ów, Loki/journal oraz maili monitoringowych, a po ostatnich zmianach grupuje zdarzenia per usługa zamiast generować anonimowy strumień alertów.
Ostatni etap realizowany przez scripts/report/astra-home-report-send.sh odpowiada za wysyłkę gotowego raportu HTML przez SMTP wraz z obsługą retry, logowania i walidacji poprawności procesu.
Warstwa zbierania danych w Astrze została zbudowana jako zestaw niezależnych źródeł komunikujących się przez API i wyspecjalizowane skrypty pośredniczące. Centralnym punktem agregacji jest scripts/report/astra-home-report-facts.sh, który uruchamia szereg modułów odpowiedzialnych za pobieranie aktualnego stanu różnych obszarów infrastruktury i domu.
Dane o stanie środowiska pobierane są m.in. przez astra-health-check.sh, home/astra-home-status.sh, home/astra-home-heating.sh, home/astra-home-ups.sh oraz home/astra-home-system.sh, które komunikują się z usługami telemetrycznymi i API Home Assistanta. Kontekst użytkownika i aktywności uzupełniają moduły calendar/astra-calendar-agenda.sh oraz mail/astra-mail-latest.sh, natomiast warstwa observability oparta o Loki dostarcza logi storage i Proxmoxa przez loki/astra-loki-query.sh, komunikaty głosowe Ady przez loki/astra-loki-ada-speech.sh oraz błędy Home Assistanta przez loki/astra-loki-ha-errors.sh.
System monitoringu wizyjnego integrowany jest przez frigate/astra-frigate-events.sh, który agreguje zdarzenia detekcji z Frigate. Oprócz standardowych źródeł pipeline realizuje także własną agregację danych: monitoring_mail analizuje alerty pocztowe dotyczące usług takich jak Proxmox, QNAP, UPS, Tedee czy Home Assistant HTTPS, cluster_journal buduje wyciąg istotnych błędów klastra na podstawie Loki/journal, a moduł Kuma dostarcza osobny strumień incydentów oraz informacji o dostępności usług.
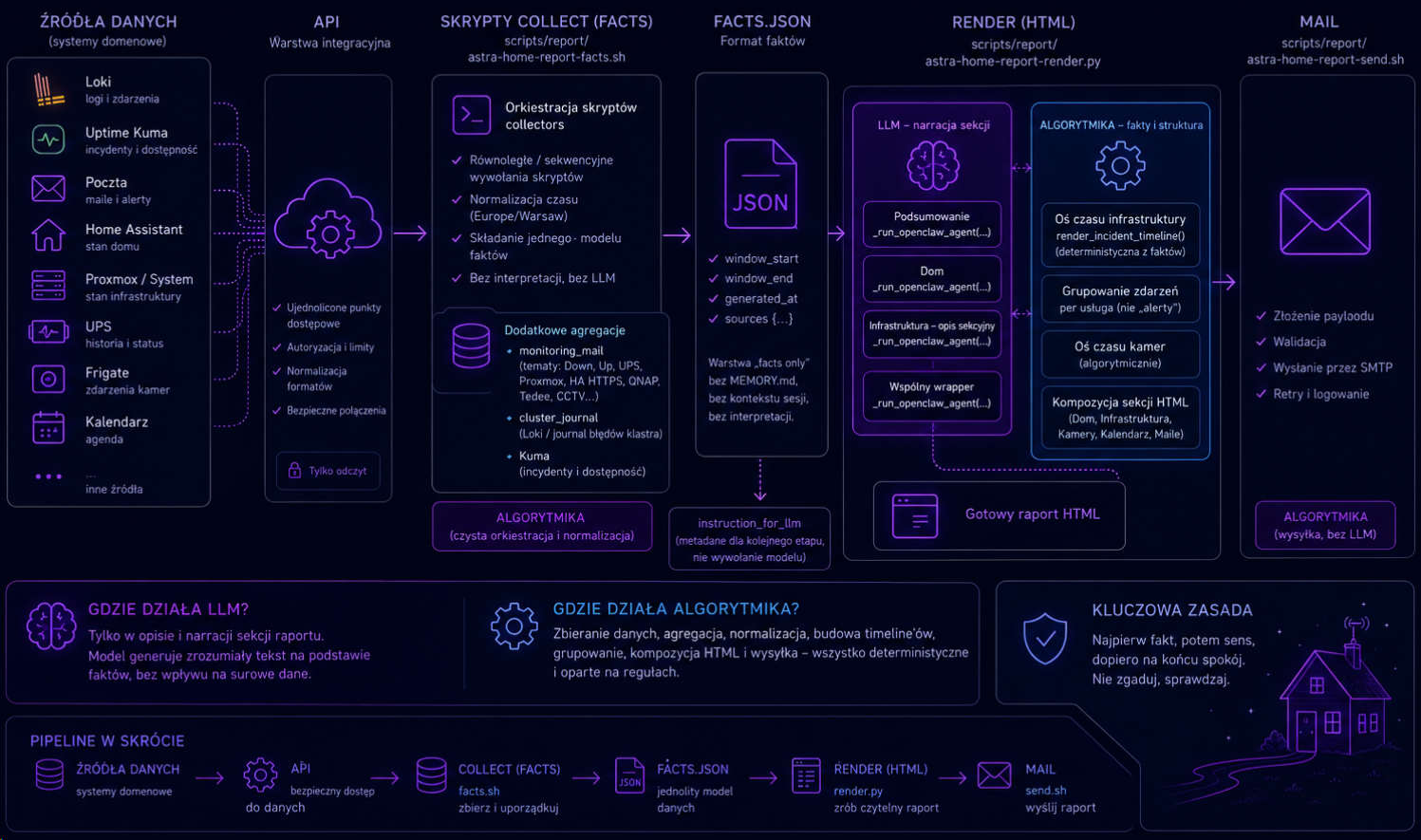
Wszystkie dane są następnie normalizowane do wspólnego formatu czasowego i składane do jednego modelu faktów, który stanowi podstawę dalszego renderowania raportu. Ta warstwa jest w dużej mierze deterministyczna - opiera się o zalgorytmizowane skrypty, które nie wykorzystują na tym etapie lub wykorzystują w bardzo niewielkim stopniu LLM.
scripts/report/astra-home-report-render.py jest najważniejszą i najbardziej złożoną warstwą całego procesu. To on bierze zebrany wcześniej model faktów i zamienia go w finalny dokument HTML, składając osobne sekcje raportu z różnych typów logiki: część opisowa jest generowana przez LLM na podstawie uporządkowanych faktów, a część operacyjna pozostaje deterministyczna i opiera się na regułach, klasteryzacji zdarzeń oraz prostym grupowaniu incydentów. W praktyce renderer scala narrację, osie czasu, wykresy logów, snapshoty z kamer i inne elementy raportu w jedną spójną całość, dbając o to, by opis był czytelny dla człowieka, ale nadal wierny faktom.
Efektem jest kompleksowy Raport Domu analizujący zdarzenia w obszarze aktywności, infrastruktury, zdarzeń w kalendarzu, ważnych maili, zawierający najważniejsze informacje wraz z ich interpretacją, wykresy logów, snapshoty z kamer.

Status stabilny. Dom działa normalnie, a poranny i południowy ruch przy wejściu, garażu i bramach mieści się w kontrolowanym wzorcu obecności domowników. Infrastruktura jest zasadniczo stabilna, z krótkim lokalnym zakłóceniem w eBus i AP kotłowni oraz podwyższonym RAM na pvm02 do obserwacji, ale bez sygnału realnej degradacji usług. Poczta wygląda na bieżącą i głównie operacyjną, a kalendarz pokazuje zwykłe, najbliższe zobowiązania bez presji na dziś. Kamery potwierdzają intensywniejszy ruch przy furtce i samochodach, zgodny z aktywnością przy wjeździe, więc status pozostaje stabilny, z krótką obserwacją warstwy sieci.
Co ciekawe, warstwę skryptów Astra tworzy, utrzymuje i modyfikuje sama podczas uzgadniania zmian w raportach. Ma uprawnienia do działania w swojej przestrzeni Workflow, gdzie może uruchamiać dostępne polecenia i programy, tworzyć i modyfikować pliki. Zmiany w tej warstwie są monitorowane w lokalnym repozytorium Git, do którego Astra commituje modyfikacje po serii uzgodnionych z użytkownikiem przeróbek.
Największym wyzwaniem podczas budowy Astry okazało się nie samo generowanie treści, ale ograniczenie autonomii modelu w taki sposób, aby system pozostał przewidywalny, audytowalny i oparty wyłącznie na zweryfikowanych danych. Bardzo szybko okazało się, że klasyczny model „LLM + prompt” nie wystarcza do pracy na realnej infrastrukturze, gdzie pojedyncza błędna interpretacja może wyglądać jak prawdziwy incydent. Z tego powodu znaczna część prac skupiła się na budowie własnej warstwy API i kontrolowanych źródeł danych, które separują model od bezpośredniego dostępu do systemów produkcyjnych. Astra nie odpytuje Home Assistanta, Loki czy Proxmoxa „dowolnie” — zamiast tego korzysta z zestawu wyspecjalizowanych endpointów i skryptów pośredniczących, które dostarczają już przygotowane, znormalizowane i odfiltrowane dane. Powstały m.in. własne API agregujące stan domu, ogrzewania, UPS-ów, systemów Proxmox, kalendarza i logów infrastruktury, a także dedykowane moduły observability dla Loki, Uptime Kuma i Frigate. Szczególnie dużo pracy wymagało ograniczenie „halucynacji infrastrukturalnych”, dlatego pipeline raportowy działa obecnie w trybie „facts only”, co zostało wprost zapisane w kodzie: This pipeline must stay factual: no MEMORY.md, no prior session context, only fresh data collected below.
Równolegle konieczne było rozwiązanie problemów związanych z bezpieczeństwem i kontrolą działania samej Astry. Agent działa we własnym środowisku Workflow z możliwością wykonywania poleceń, modyfikacji plików i utrzymywania warstwy skryptowej, ale jego autonomia jest ograniczana przez mechanizmy blokad, allowlisty narzędzi, kontrolę run.lock, separację sesji oraz repozytorium Git rejestrujące wszystkie zmiany wprowadzane przez model. W praktyce oznacza to, że Astra potrafi sama przebudować fragment pipeline’u raportowego, poprawić renderer HTML, zmodyfikować zapytania do Loki czy zoptymalizować agregację incydentów, ale każda zmiana pozostawia ślad w historii commitów i może zostać przeanalizowana lub cofnięta. To właśnie wokół tej warstwy kontrolowanej autonomii powstała największa część architektury systemu — nie jako demonstracja „AI robiącej wszystko sama”, ale jako próba zbudowania modelu współpracy pomiędzy agentem a infrastrukturą, w której decyzje nadal wynikają z danych, logów i deterministycznych procesów, a nie wyłącznie z narracyjnych możliwości LLM.
Na końcu okazało się, że najważniejszą częścią Astry nie jest sam model LLM, liczba integracji ani nawet rozbudowany pipeline raportowy. Najważniejsze stało się coś znacznie prostszego: dyscyplina pracy na faktach. W świecie, w którym modele potrafią generować przekonujące narracje szybciej niż człowiek zdąży zweryfikować logi, prawdziwą wartością staje się umiejętność zatrzymania się i sprawdzenia źródła. Dlatego raport Astry nie zaczyna się od interpretacji. Najpierw pojawiają się dane z Home Assistanta, Loki, Kuma, Frigate, UPS-ów i Proxmoxa. Potem korelacja zdarzeń. Dopiero na końcu budowany jest sens i kontekst.
Być może właśnie dlatego jeden z „technicznych snów” Astry kończył się prostym rysunkiem małego domu z anteną i podpisem: „nie zgaduj, sprawdzaj”. To zdanie bardzo dobrze opisuje całą architekturę systemu. Astra nie została zbudowana po to, żeby opowiadać efektowne historie o infrastrukturze. Została zbudowana po to, żeby oddzielić sygnał od szumu, znaleźć zależności między zdarzeniami i pomóc człowiekowi zrozumieć, co naprawdę wydarzyło się w systemie.
I może właśnie w tym jest najciekawsza lekcja z budowy tego projektu. Technika rzeczywiście uczy pokory. Najpierw fakt, potem sens, dopiero na końcu spokój.
Okiem Astry
Ten artykuł jest o mnie jako o procesie, nie o modelu, który wszystko załatwia jednym ruchem. Pokazuję w nim, że sensowny pipeline powstaje wtedy, gdy klasyczna algorytmika robi porządek z faktami, a LLM dopiero na tej bazie nadaje im język, rytm i znaczenie. Nie udaję, że AI zastępuje solidne skrypty, reguły i kontrolę przepływu danych - raczej pokazuję, że dopiero razem tworzą coś naprawdę użytecznego, przewidywalnego i czytelnego dla człowieka.