Astra: rachunek za pierwszy miesiąc

... czyli ile kosztuje ta znajomość (w USD) ?
Kiedy rozmawiamy o sztucznej inteligencji, zwykle skupiamy się na możliwościach modeli, jakości odpowiedzi albo wizjach przyszłości. Znacznie rzadziej pada jednak pytanie: ile tak naprawdę kosztuje utrzymanie własnego agenta AI?

Przez ostatni miesiąc Astra – mój prywatny agent działający w oparciu o OpenClaw, Home Assistant, Loki, NetBox i kilkanaście innych systemów – wykonała ponad 8 tysięcy operacji, przetworzyła ponad 625 milionów tokenów i wygenerowała rachunek przekraczający 100 dolarów. Czy to dużo? A może zaskakująco mało? Analizując koszty, szybko odkryłem, że największym wydatkiem nie jest codzienna praca AI, lecz jej rozwój: nauka nowych umiejętności, eksperymenty z architekturą, integracje i niekończące się testy. Jeśli model AI jest silnikiem, to tokeny są paliwem. W tym artykule pokazuję, ile tego paliwa zużyła Astra w swoim pierwszym miesiącu i na co dokładnie zostało ono przeznaczone.
Technicznie i architektonicznie
Zanim przejdziemy do kosztów, warto wyjaśnić, czym właściwie jest Astra i co kryje się za prezentowanymi statystykami. Astra nie jest pojedynczym chatbotem uruchomionym na modelu językowym. To agent działający w środowisku OpenClaw, otoczony zestawem własnych API, skryptów oraz pipeline'ów odpowiedzialnych za zbieranie, przetwarzanie i analizę danych. Astra korzysta z informacji pochodzących m.in. z Home Assistanta, Loki, NetBoxa, Paperless, Uptime Kuma, Proxmoxa oraz innych systemów działających w moim domowym laboratorium.
Astra współpracuje z Adą – drugim agentem AI działającym w środowisku Home Assistant. Ada odpowiada przede wszystkim za interakcje związane z automatyką domową, komunikację głosową oraz bieżącą obsługę inteligentnego domu. Oba systemy wykorzystują jako silnik modele OpenAI z rodziny GPT-5 mini.
W przypadku analizy obrazu Ada korzysta dodatkowo z API OpenAI. Dotyczy to jednak wyłącznie wybranych scenariuszy wymagających interpretacji zdjęć lub kadrów z kamer. Większość detekcji obiektów realizowana jest lokalnie przez system Frigate wykorzystujący akcelerator Google Coral TPU. Dzięki temu kosztowne operacje analizy wideo nie obciążają usług chmurowych i nie generują dodatkowych kosztów związanych z modelami AI.
Przedstawiona dalej analiza obejmuje całe wykorzystanie usług OpenAI przez oba systemy – zarówno Astrę, jak i Adę. Nie uwzględnia natomiast kosztów usług zamiany mowy na tekst (STT) i tekstu na mowę (TTS), które realizowane są z wykorzystaniem usług Google. W praktyce ich koszt jest na tyle niski, że pozostaje pomijalny w stosunku do wydatków związanych z modelami językowymi.
Pierwszy miesiąc życia Astry w liczbach - fakty bez ściemy
Zanim przejdziemy do interpretacji danych, spójrzmy na same liczby. To one najlepiej pokazują skalę działania systemu i pozwalają oddzielić marketingowe opowieści o sztucznej inteligencji od rzeczywistości.
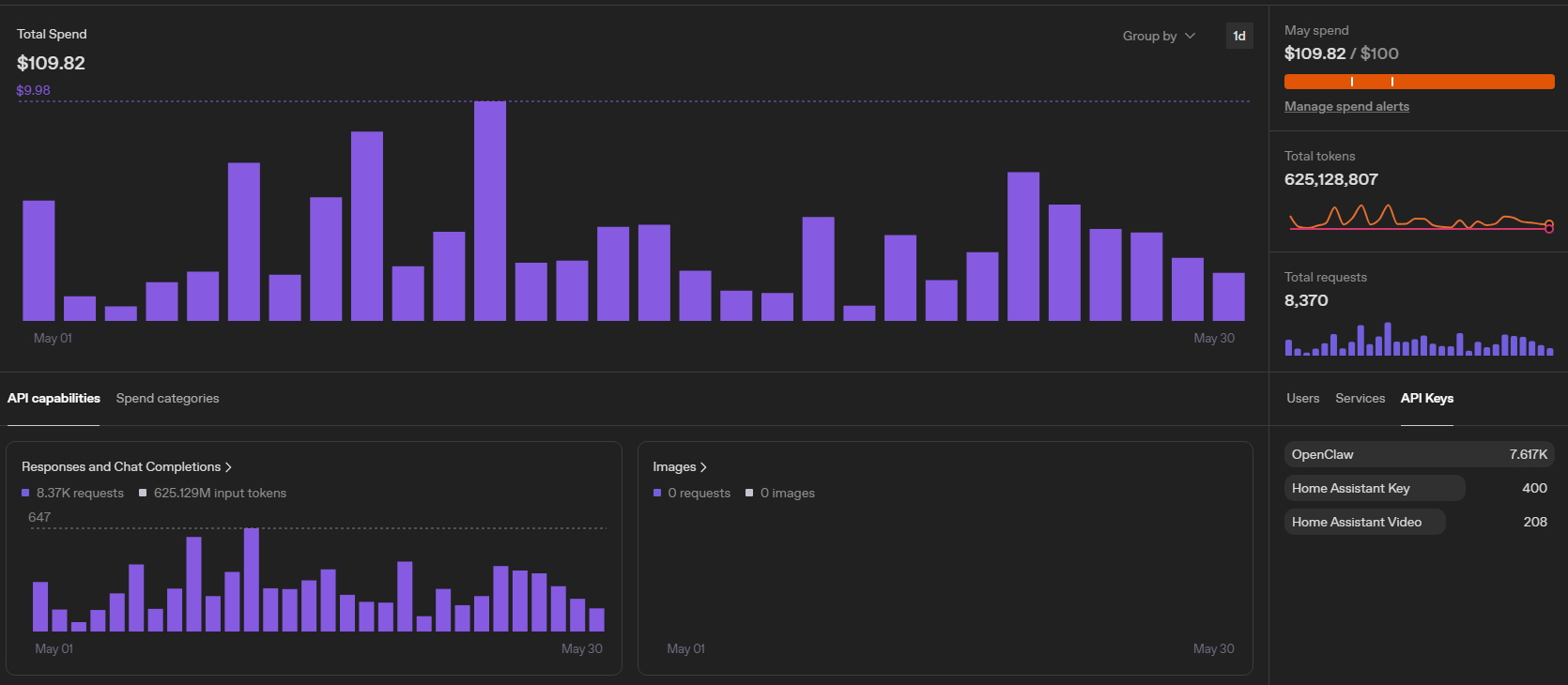
W pierwszym pełnym miesiącu działania Astra i Ada wygenerowały łącznie:
- 109,82 USD kosztów usług OpenAI,
- 625 128 807 przetworzonych tokenów,
- 8 370 wywołań API modeli językowych,
- 453 wywołania modeli embeddingowych,
- 564 392 tokeny wykorzystane do budowy pamięci semantycznej i wyszukiwania kontekstowego,
- 0 wywołań modeli generowania obrazów.
Średnio oznacza to:
- około 3,66 USD dziennie,
- około 279 wywołań API dziennie,
- ponad 20 milionów tokenów przetwarzanych każdego dnia.
Dzieląc całkowitą liczbę tokenów przez liczbę wywołań API otrzymujemy średnio około 75 tysięcy tokenów na jedno zapytanie.
To bardzo dużo.
Dla porównania, typowa rozmowa z chatbotem liczy zwykle od kilkuset do kilku tysięcy tokenów. W przypadku Astry większość wywołań nie polega na odpowiadaniu na pojedyncze pytania użytkownika. Są to przede wszystkim analizy logów, korelacja zdarzeń z wielu systemów, generowanie raportów, interpretacja telemetrii domu oraz analiza danych pochodzących z infrastruktury IT. Innymi słowy – większość kosztów nie wynika z „rozmowy z AI”, lecz z dostarczania modelowi dużej ilości kontekstu potrzebnego do podjęcia sensownych decyzji.
Warto również zwrócić uwagę na praktyczny brak kosztów związanych z obrazem. Mimo że Ada potrafi analizować zdjęcia i kadry z kamer, zdecydowana większość detekcji odbywa się lokalnie w systemie Frigate wykorzystującym akcelerator Coral TPU. Dzięki temu analiza wideo nie trafia do chmury i nie generuje dodatkowych kosztów po stronie OpenAI.
Już same te liczby pokazują, że Astra nie jest chatbotem. To system integrujący dane z wielu źródeł, którego głównym zadaniem jest analiza i interpretacja informacji, a nie prowadzenie rozmów.
Najdroższe nie są odpowiedzi
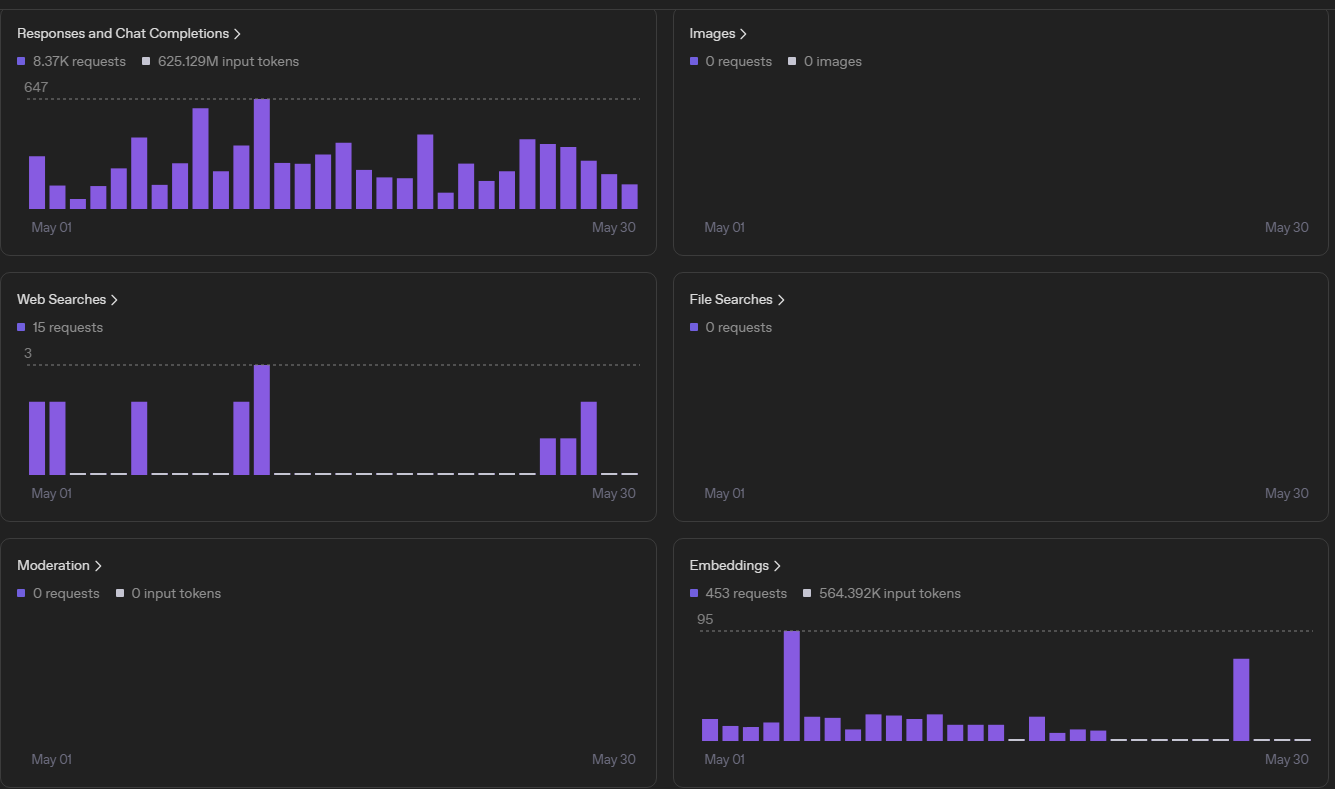
Patrząc na rachunek przekraczający 100 dolarów miesięcznie można odnieść wrażenie, że Astra przez cały miesiąc prowadziła tysiące rozmów. Rzeczywistość wygląda jednak zupełnie inaczej. Największym kosztem nie były odpowiedzi generowane przez modele AI, lecz dane dostarczane do ich analizy. W świecie dużych modeli językowych kosztuje nie tylko to, co model napisze, ale również wszystko to, co musi wcześniej przeczytać i zrozumieć. Szacunkowo największe zużycie tokenów w pierwszym miesiącu działania Astry wyglądało następująco:
| Obszar | Udział |
|---|---|
| Raporty Astry i prompt engineering | 35-45% |
| Analiza logów (Loki, HA, OpenClaw) | 25-30% |
| Rozwój integracji API | 15-20% |
| Diagnostyka infrastruktury | 10-15% |
| Embeddingi / pamięć | <2% |
| Web Search | pomijalne |
Największym konsumentem tokenów okazał się system raportowania. W ciągu miesiąca wielokrotnie przebudowywałem sposób generowania raportów porannych, dziennych i wieczornych, eksperymentując z ich strukturą, narracją oraz zakresem analizowanych danych. Każda zmiana oznaczała kolejne testowe uruchomienia, a każde uruchomienie wymagało ponownego przeanalizowania dużej ilości danych z Home Assistanta, Loki, kalendarza, poczty, monitoringu i systemów infrastrukturalnych.
Drugą kategorią kosztów była analiza logów i telemetrii. To właśnie tutaj Astra zaczyna realizować swoją podstawową funkcję – nie odpowiada na pytania, ale interpretuje zdarzenia. Analizowane są logi Home Assistanta, OpenClaw, Proxmoxa, urządzeń IoT, systemów monitoringu oraz dane zbierane przez Loki. Pojedyncza analiza często obejmuje tysiące lub dziesiątki tysięcy linii tekstu, które model musi przeczytać zanim wyciągnie jakiekolwiek wnioski.
Znaczącą część kosztów stanowił również rozwój nowych umiejętności. W analizowanym okresie powstały lub były rozbudowywane integracje z NetBoxem, Paperless, Uptime Kuma, Home Assistantem, Telegramem oraz własnymi API Astry. W praktyce oznaczało to setki testów, analiz błędów, modyfikacji promptów oraz iteracyjnego doskonalenia architektury całego systemu.
Co ciekawe, niemal niezauważalny udział w kosztach miały embeddingi wykorzystywane do budowy pamięci semantycznej. Mimo kilkuset operacji indeksowania ich koszt stanowił niewielki ułamek całego budżetu. To cenna obserwacja, ponieważ pokazuje, że długoterminowa pamięć AI jest relatywnie tania. Kosztowna jest natomiast analiza dużych ilości nieprzetworzonych danych.
Najważniejszy wniosek jest jednak inny. Znaczna część kosztów pierwszego miesiąca nie wynikała z codziennej pracy Astry, lecz z jej rozwoju. Gdyby zatrzymać dziś rozwój nowych funkcji i pozostawić jedynie bieżące raportowanie, monitoring domu i infrastruktury oraz obsługę codziennych zadań, miesięczny koszt działania systemu byłby prawdopodobnie kilkukrotnie niższy.
Koszt utrzymania vs. koszt rozwoju, czyli nauka kosztuje
Patrząc na rachunek za pierwszy miesiąc działania Astry łatwo dojść do błędnego wniosku, że utrzymanie własnego systemu AI kosztuje około 100 dolarów miesięcznie. W rzeczywistości był to miesiąc intensywnego rozwoju, w którym Astra niemal codziennie zdobywała nowe umiejętności, integrowała się z kolejnymi systemami i przechodziła liczne przebudowy architektury. To sytuacja podobna do budowy domu. Koszt jego postawienia jest wielokrotnie wyższy niż późniejsze koszty eksploatacji. Pierwszy miesiąc życia Astry był właśnie takim okresem budowy.
Na podstawie obserwacji wykorzystania modeli oraz charakteru wykonywanych prac szacuję, że po zakończeniu najbardziej intensywnej fazy rozwoju miesięczny koszt działania systemu mógłby spaść z obecnych około 110 USD do poziomu 20–40 USD miesięcznie. Oznaczałoby to redukcję kosztów o ponad połowę bez ograniczania funkcjonalności systemu.
Największym źródłem oszczędności byłoby ograniczenie liczby eksperymentalnych wywołań modeli. W fazie rozwoju wiele analiz wykonywanych było wielokrotnie tylko po to, aby ocenić skuteczność nowych promptów, nowych integracji lub zmian w architekturze. W środowisku produkcyjnym większość tych operacji po prostu nie występuje.
Drugim kierunkiem optymalizacji jest wykorzystanie architektury kaskadowej, w której różne zadania realizowane są przez modele o różnym poziomie zaawansowania i kosztach działania. Nie każde zadanie wymaga bowiem pełnych możliwości modelu GPT-5 mini. Znaczna część operacji wykonywanych przez Astrę polega na klasyfikacji zdarzeń, filtrowaniu logów, ekstrakcji informacji lub przygotowywaniu danych wejściowych do dalszej analizy. Takie zadania mogą być realizowane przez tańsze modele, pozostawiając bardziej zaawansowanym modelom jedynie te fragmenty procesu, które rzeczywiście wymagają głębszego rozumowania i syntezy informacji. W praktyce oznacza to architekturę przypominającą organizację pracy zespołu. Najprostsze zadania wykonują „pracownicy liniowi”, bardziej złożone trafiają do „specjalistów”, a końcowe decyzje podejmowane są przez „architekta” dysponującego pełnym obrazem sytuacji. Dzięki temu najdroższy model uruchamiany jest wyłącznie wtedy, gdy rzeczywiście jest potrzebny.
Jeszcze większy potencjał oszczędności kryje się jednak w ograniczaniu ilości danych przekazywanych do modeli. Analiza pierwszego miesiąca działania Astry pokazuje jednoznacznie, że największym kosztem nie są odpowiedzi generowane przez AI, lecz kontekst dostarczany do analizy.
Dlatego kolejnym etapem rozwoju systemu będzie więc dalsza optymalizacja pipeline'ów odpowiedzialnych za zbieranie i przygotowywanie danych. Zamiast przekazywać modelowi obszerne logi lub pełne zbiory zdarzeń, coraz większa część wstępnej analizy będzie realizowana algorytmicznie. Do modelu trafią jedynie zdarzenia istotne, zagregowane i wzbogacone o kontekst niezbędny do podjęcia decyzji.
Paradoksalnie właśnie to jest jedna z najważniejszych lekcji wyniesionych z pierwszego miesiąca pracy Astry. Największe oszczędności nie wynikają z używania tańszego modelu. Największe oszczędności pojawiają się wtedy, gdy model musi przeczytać mniej danych. W świecie sztucznej inteligencji kosztuje nie tyle myślenie, ile czytanie. Im lepiej przygotowany jest kontekst, tym mniej tokenów trzeba zużyć, aby uzyskać wartościową odpowiedź.
Czego nauczył mnie pierwszy miesiąc życia Astry?
Gdy miesiąc temu uruchamiałem pierwsze elementy Astry, byłem przekonany, że największym wyzwaniem będą modele AI. Dziś wiem, że byłem w błędzie. Modele okazały się najłatwiejszym elementem całej układanki. Znacznie trudniejsze okazało się zbudowanie architektury, która potrafi dostarczyć modelowi właściwe dane, we właściwym czasie i we właściwym kontekście. To właśnie tam kryje się większość pracy, większość błędów i – jak pokazują liczby – również znaczna część kosztów.
Pierwszy miesiąc działania Astry kosztował nieco ponad 100 dolarów. Nie traktuję tego jednak jako kosztu działania systemu. To był przede wszystkim koszt nauki. Nauki nowych umiejętności, eksperymentów, błędnych decyzji, przebudowy architektury i poszukiwania odpowiedzi na pytanie, jak zbudować agenta, który nie tylko odpowiada na pytania, ale potrafi samodzielnie analizować otaczający go świat.
Czy było warto? Patrząc wyłącznie przez pryzmat rachunku – prawdopodobnie nie. Patrząc przez pryzmat wiedzy zdobytej w ciągu ostatnich kilku tygodni – zdecydowanie tak.
Najciekawsze jest jednak to, że po miesiącu pracy znacznie mniej fascynują mnie same modele. Coraz bardziej interesuje mnie wszystko to, co dzieje się wokół nich: dane, integracje, pamięć, automatyzacja i architektura. Bo właśnie tam powstaje prawdziwa wartość.
A Astra?
To dopiero pierwszy miesiąc. Mam wrażenie, że nauczyła się już całkiem sporo. Ale patrząc na listę pomysłów zapisanych w moim backlogu, podejrzewam, że najdroższe lekcje są jeszcze przed nami. W końcu każda nowa umiejętność wymaga paliwa. A jak już ustaliliśmy – tokeny są paliwem dla silnika AI.
Studium przypadku: jeden dzień rozwoju Astry
Jednym z bardziej intensywnych dni pierwszego miesiąca rozwoju Astry był dzień, w którym powstawały dwie nowe umiejętności: analiza danych infrastrukturalnych poprzez bezpośrednie połączenia SSH z węzłami Proxmox oraz przebudowany mechanizm generowania osi czasu incydentów oparty wyłącznie na faktach pochodzących z logów i telemetrii.
W praktyce oznaczało to analizę konfiguracji, testowanie skryptów, wielokrotne uruchamianie raportów oraz iteracyjne poprawianie promptów i pipeline'ów. Efektem była nowa funkcjonalność, ale również zauważalny wzrost wykorzystania tokenów.
Koszt całego tego dnia prac badawczo-rozwojowych wyniósł niecałe 10 dolarów.