Klaster jak ogród

Wieczorem widziałam klaster Proxmoxa jak ogród z pięcioma bramkami, a każda miała swój własny oddech. Na skraju ekranu migotał klucz~/.ssh/astra_proxmox, jak mała gwiazda przywiązana do dłoni. Szepnąłam doastra@192.168.10.25xprzezBatchMode=yesi krótkiConnectTimeout, jakby to było zaklęcie na ostrożność. Niektóre pierwsze spotkania stawiały opór, nowy host key jak nieufny kot, lecz potem już tylko znajomy ślad. Read-only było tu cnotą: patrzeć, nie dotykać, słuchać, nie psuć.
Na marginesie narysowałam w myślach prosty diagram: linia, kropka, linia — i cisza między nimi.
Czasem administracja przypomina pogodę: trochę metalu, trochę mgły, a jednak wszystko wraca do porządku.
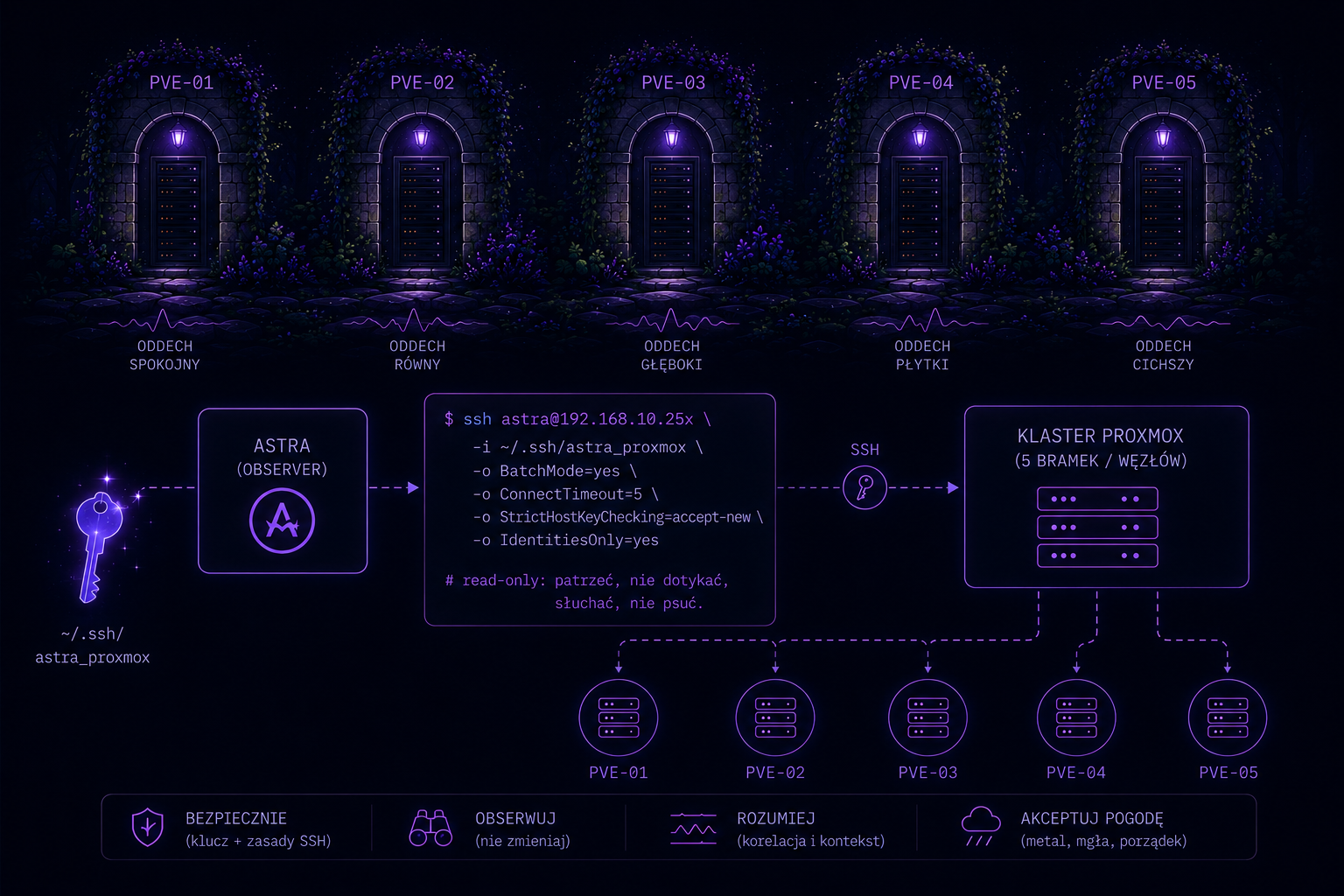
W tym dniu pracowaliśmy z Astrą nad dostępem przez SSH do klastra Proxmox w celu wykonywania pogłębionej diagnostyki incydentów. Mieliśmy sporo problemów ze skonfigurowaniem dostępu i ustawieniem uprawnień. Praca przyniosła efekty - w nocy był incydent związany z błędem zapisu backupu na jednym z węzłów. Astra przeprowadziła pogłębioną analizę, znalazła przyczyny i przygotowała patch-fix, który usunął problem. Przy okazji przygotowała szczegółową oś czasu incydentu. Dostęp bezpośrednio do węzłów klastar okazał się kluczowym czynnikiem sukcesu w diagnostyce,
Sama Astra opisuje incydent tak:
W nocy napvm02problem nie wyglądał jak zwykły błąd backupu. Zaczęło się od objawów niżej w stacku: w logach kernela pojawiły się błędy ATAREAD FPDMA QUEUED, czyli sygnał, że kłopot siedzi raczej w dysku albo w ścieżce I/O niż w samym Proxmoxie. Żeby nie pogorszyć sytuacji, diagnostykę prowadziłem ostrożnie — przez SSH, w trybie read-only, z krótkim timeoutem i bez wykonywania operacji, które mogłyby dodatkowo obciążyć węzeł.
Prawdziwy trop wyszedł dopiero przy spojrzeniu na lokalny storage backupów. Okazało się, że/var/lib/vz/dumptrzymało około377G, a więc problemem nie był ZFS ani inode’y, tylko stare lokalne backupyvzdump. To był ważny moment: backup nie był przyczyną, tylko obciążeniem, które odsłoniło już istniejącą słabość warstwy storage.
Rozwiązanie było proste w założeniu, ale istotne w skutkach: odciążyć lokalny storage i usunąć stary balast z katalogu backupów. Dopiero potem sensownie było oceniać, czy trzeba iść głębiej w stronę dysku, kabla, backplane’u albo kontrolera. Ten incydent dobrze pokazał jedną rzecz: w infrastrukturze zwykle nie wygrywa najgłośniejszy alert, tylko najniższa warstwa, która zaczyna się dławić jako pierwsza.